If you want to know what motivated me to create TrueShelf (an AI powered adaptive learning platform) and the future of learning, please read my interview on Edsurge.
algorithms
Personalization in Polytopix
Today’s blog post is a quick announcement of “personalization” feature in Polytopix. We added a new feature that allows users to add their (possibly multiple) twitter accounts in Polytopix. The user’s twitter stream is used to personalize and rank the news articles on Polytopix. More importantly, our semantic similarity algorithms will display contextual explanatory articles along-side the news articles in the user’s feed.

Weekly news digest from Polytopix
On popular demand, we added a new feature called “weekly news digest” in Polytopix. Our ranking algorithm picks the top (at most 10) news articles (along with the contextual explanatory articles) from the last one week and emails them every Friday midnight. I will post the details of our ranking algorithm in a future blog post.
If you want to receive this weekly digest, subscribe on polytopix.com
Here is an example from the week 01/24/2015 – 01/30/2015

Starting a Startup: Polytopix
I am inaugurating this year’s blogging with some very exciting news. I am starting a startup called Polytopix. I will be finishing my spring semester teaching responsibilities at Princeton and moving to Bay Area this summer to work full-time on Polytopix.
Meanwhile, I am actively designing, coding and deploying new algorithms, hiring R&D engineers, working on legal aspects and many more related action items. For the first time, I am using a book (instead of post-it’s) to keep track of my to-do list.
I can hear the clock ticking louder and faster than usual, perhaps because I am behind my schedule. According to my original plan (enthusiastically devised during my final semester of PhD), this blog post was supposed to appear in January 2013 !! A bunch of interesting (to say the least) events contributed generously to this delay.
What is Polytopix ?
Polytopix is aimed at adding context to news articles by analyzing the semantics of the news events. Polytopix’s algorithms retrieve news articles, categorize them, analyze their semantics and augment them with contextual explanatory articles.
Why Startup ?
The main idea of ‘semantic analysis of news’ is in my mind since my undergraduate senior thesis defense in 1999. Back then, I developed a summarization engine using lexical cohesion and information retrieval algorithms. See my very first publication here. Starting from the final semester of my PhD (Spring 2011), I started developing a semantic engine to understand and analyze news, especially financial news. I used it as a stock picker to invest my savings. It performed much better than my mutual funds. This is my first realization of the potential of ‘semantic analysis’. Polytopix applies semantic analysis to daily news articles. I am planning to “spin-off” the ‘financial news analysis’ as a separate startup. More on this, in a later blog post.
You probably heard the advice “Do not do a PhD just for the sake of doing it”. The same advice applies (with much more emphasis) to starting a startup. You should only start a startup if you are really passionate to solve a particular problem and you are strongly convinced that starting a company is the best way to solve it. I have all the right reasons to start Polytopix.
How do I feel now ?
Well, I am feeling very excited and energetic. The roadmap looks very challenging.

Review: Algorithms Unplugged, The Power of Algorithms
In my last post, I said my next post will be about one of my papers on directed minors. But that paper is taking more time to write than I expected. Meanwhile, here is my review of two algorithms textbooks: Algorithms Unplugged and The Power of Algorithms, to appear in the SIGACT book review column soon.
Merry Christmas and Happy New Year to everybody !!


——————————————————————————————————–
Introduction
Algorithms play an integral part in our daily lives. They are everywhere. They help us travel efficiently, retrieve relevant information from huge data sets, secure money transactions, recommend movies, books, videos, predict stock market etc. Algorithms are essentially simple extensions of our daily rational thinking process. It is very tough to think about a daily task that does not benefit from efficient algorithms. Often the algorithms to solve our daily tasks are very simple, yet their impact is tremendous.
Most of the common books on algorithms start with sorting, searching, graph algorithms and conclude with NP-completeness and perhaps some approximation and online algorithms. The breadth of algorithms cannot be covered by a single book. Algorithms Unplugged and The Power of Algorithms take different approach compared to standard Algorithms textbooks. They are aimed at explaining several basics algorithms (written by multiple authors) in an intuitive manner with real-life examples, without compromising the details. This is how algorithms should be taught.
Algorithms Unplugged
This book is divided into four major parts. Each part has several chapters. Here is an overview of these parts and chapters.
Part I: The first part is about sorting and systematic search i.e., finding things quickly. Chapter 1 introduces binary search, one of the most basic search strategies. A recursive implementation of binary search is explained using an intuitive example to find a CD is a sorted sequence of CD’s. Chapter 2 explains insertion sort, one of the most intuitive comparison-based sorting algorithms and Chapter 3 explains merge sort and quick sort, two sorting algorithms based on the divide and conquer paradigm. Chapter 4 explains bitonic sorting circuit to implement a parallel sorting algorithm. Chapter 5 describes topological sorting and explains how to schedule jobs without violating any dependencies between jobs. Chapter 6 considers string searching problem and explains the Boyer-Moore-Horspool algorithm. Chapter 7 considers the search problem in several real-world applications and explains the depth first search algorithm. Chapter 8 explains how to escape from a dark labyrinth using Pledge’s algorithm. Chapter 9 defines strongly-connected components in directed graphs and explains how to efficiently find directed cycles. Chapter 10 introduces basic principles of search engines, introduces PageRank and explains how to find relevant pages in the World-Wide Web.
Part II: The second part deals with arithmetic problems, number theoretic, cryptographic, compression and coding algorithms. Chapter 11 presents Karatsuba’s method of multiplying long integers that is much more efficient than the basic grade school method. Chapter 12 explains how to compute the greatest common divisor of two numbers using the centuries old Euclidean algorithm. Chapter 13 explains the Sieve of Eratosthenes, a practical algorithm to compute the table of prime numbers. Chapter 14 introduces the basics of one-way functions which play a crucial role in the following chapters. Chapter 15 presents One-Time-Pad, a basic symmetric cryptographic algorithm. Chapter 16 explains Public-Key Cryptography, an asymmetric cryptographic method using different keys for encryption and decryption. Chapter 17 explains how to share a secret in such a way that all participants must meet to decode the secret. Chapter 18 presents a method to play poker by email using cryptographic methods. Chapter 19 and 20 presents fingerprinting and hashing techniques to compress large data sets so that they can be compared using only a few bits. Chapter 21 introduces the basics of coding algorithms to protect data against errors and loss.
Part III: The third part deals with strategic thinking and planning. Chapter 22 discusses broadcasting algorithms to disseminate information quickly. Chapter 23 presents algorithms to convert numbers into english words. Chapter 24 explains majority algorithms with applications and extensions. Chapter 25 explains how to generate random numbers. Chapter 26 discusses winning strategies for a matchstick game. Chapter 27 discusses algorithms to schedule sports leagues. Chapter 28 characterizes eulerian circuits and presents algorithms to find them. Chapter 29 details how to approximately draw circles on a pixelated screen. Chapter 30 explains Gauss-Seidel iterative method. Chapter 31 presents a dynamic programming algorithm to compute distance between two DNA sequences.
Part IV: The final part is about optimization problems. Chapter 32, 33 and 34 describes shortest path, minimum spanning tree and maximum-flow algorithms, three basic optimization problems. Chapter 35 discusses stable marriage problem and presents an algorithm to find a stable matching in a bipartite graph. Chapter 36 explains an algorithm to find the smallest enclosing cycle of a given set of points. Chapter 37 presents online algorithms for the Ski-Rental and Paging problems. Chapter 38 and 39 discusses the Bin-Packing and the Knapsack problems. Chapter 40 discusses the Traveling Salesman Problem, one of the most important optimization problems that challenged mathematicians and computer scientists for decades. Chapter 41 introduces Simulated Annealing method to solve a basic tiling problem and the Traveling Salesman Problem.
At the end of every chapter there are references for further reading. Readers are highly encouraged to go through these references to get better understanding of the corresponding concepts.
The Power of Algorithms
This book is divided into two major parts. Each part has several chapters. Here is an overview of these parts and chapters.
Part I: The first part is divided into three chapters. Chapter 1 gives a historical perspective of algorithms, origin of the word {\em algorithm}, recreational algorithms and reasoning with computers. Chapter 2 aims at explaining how to design algorithms by introducing the basics of graph theory and two algorithms techniques: the backtracking technique and the greedy technique. Chapter 3 quickly introduces the complexity classes P and NP and the million dollar P vs NP problem.
Part II: The second part is aimed at explaining several algorithms of daily life. Chapter 4 explains the Shortest Path problems, one of the basic optimization problems. Chapter 5 discusses the basics of Internet and Web Graphs and explains several related algorithms to Crawl, Index and Search the Internet. Chapter 6 discusses the basics of cryptographic algorithms such as RSA and digital signatures. Chapter 7 discusses biological algorithms. Chapter 8 explains networks algorithms with transmission delays. Chapter 9 discusses algorithms for auctions and games. It presents Prisoner’s dilemma, Coordination games, Randomized strategies, Zero-sum games, Nash’s Theorem, Spurners Lemma, Vickery-Clarke-Groves auctions and competitive equilibria. Chapter 10 explains the power of randomness and its role in complexity theory.
At the end of every chapter there are Bibliographic Notes with several pointers for further reading.
Opinion
Overall I found these two books very interesting and well-written. There is a nice balance between informal introductions and formal algorithms. It was a joy for me to read these books and I recommend them to anyone (including beginners) who is curios to learn some of the basic algorithms that we use in our daily lives in a rigorous way. I strongly encourage you to read these two books even if you have already read a bunch of algorithms books.
There is no prerequisite to follow these books, except for a reasonable mathematical maturity and perhaps some familiarity with basic constructs of at least one programming language. They can be used as a self-study text by undergraduate and advanced high-school students. In terms of being used in a course, some of the topics in these books can be used in an undergraduate algorithms course. I would definitely suggest that you get them for yourself or your university/department library.
——————————————————————————————————–
How to learn Vocabulary efficiently ?
Today’s post is very similar to one of my earlier posts titled “How to teach Algorithms ?“. In that earlier post, I announced an Algorithms App for iPad. Recently, I ported Algorithms App to Mac. Today’s post is about “How to learn Vocabulary efficiently ?”.
This summer, I went to a local bookstore to checkout the vocabulary section. There are several expensive books with limited number of practice tests. I also noticed a box of paper flashcards (with only 300 words) for around $25 !!! After doing some more research, I realized that the existing solutions (to learn english vocabulary) are either too hard to use and/or expensive and/or old-fashioned.
So I started building an app with ‘adaptiveness’ and ‘usability’ as primary goals. The result is the Vocabulary App (for iPhone and iPad). Here is a short description of my app.
Vocabulary app uses a sophisticated algorithm (based on spaced repetition and Leitner system) to design adaptive multiple-choice vocabulary questions. It is built on a hypergraph of words constructed using lexical cohesion.
Learning tasks are divided into small sets of multiple-choice tests designed to help you master basic words before moving on to advanced words. Words that you have the hardest time are selected more frequently. For a fixed word, the correct and wrong answers are selected adaptively giving rise to hundreds of combinations. After each wrong answer, you receive a detailed feedback with the meaning and usage of the underlying word.
Works best when used every day. Take a test whenever you have free time.
Go ahead and download the Vocabulary App and let me know your feedback/opinion (or) suggest new features.
At any given waking moment I spend my time either (1) math monkeying around (or) (2) code monkeying around. During math monkeying phase, I work on math open problems (currently related to directed minors). During code monkeying phase, I work on developing apps (currently Algorithms App, Vocabulary App) or adding new features to my websites TrueShelf or Polytopix. I try to maintain a balance between (1) and (2), subject to the nearest available equipment (a laptop or pen-and-paper). My next post will be on one of my papers (on directed minors) that is nearing completion. Stay tuned.
Open problems for 2014
Wish you all a Very Happy New Year. Here is a list of my 10 favorite open problems for 2014. They belong to several research areas inside discrete mathematics and theoretical computer science. Some of them are baby steps towards resolving much bigger open problems. May this new year shed new light on these open problems.
- 1. Combinatorics : Prove that trees with diameter 6 are graceful. (see earlier posts graceful tree conjecture, graceful diameter-6 trees).
- 2. Optimization : Improve the approximation factor for the undirected graphic TSP. The best known bound is 7/5 by Sebo and Vygen.
- 3. Algorithms : Prove that the tree-width of a planar graph can be computed in polynomial time (or) is NP-complete.
- 4. Fixed-parameter tractability : Treewidth and Pathwidth are known to be fixed-parameter tractable. Are directed treewidth/DAG-width/Kelly-width (generalizations of treewidth) and directed pathwidth (a generalization of pathwidth) fixed-parameter tractable ? This is a very important problem to understand the algorithmic and structural differences between undirected and directed width parameters.
- 5. Space complexity : Is Planar ST-connectvity in logspace ? This is perhaps the most natural special case of the NL vs L problem. Planar ST-connectivity is known to be in
. Recently, Imai, Nakagawa, Pavan, Vinodchandran and Watanabe proved that it can be solved simultaneously in polynomial time and approximately O(√n) space.
- 6. Metric embedding : Is the minor-free embedding conjecture true for partial 3-trees (graphs of treewidth 3) ? Minor-free conjecture states that “every minor-free graph can be embedded in
with constant distortion. The special case of planar graphs also seems very difficult. I think the special case of partial 3-trees is a very interesting baby step.
- 7. Structural graph theory : Characterize pfaffians of tree-width at most 3 (i.e., partial 3-trees). It is a long-standing open problem to give a nice characterization of pfaffians and design a polynomial time algorithm to decide if an input graph is a pfaffian. The special of partial 3-trees is an interesting baby step.
- 8. Structural graph theory : Prove that every minimal brick has at least four vertices of degree three. Bricks and braces are defined to better understand pfaffians. The characterization of pfaffian braces is known (more generally characterization of bipartite pfaffians is known). To understand pfaffians, it is important to understand the structure of bricks. Norine,Thomas proved that every minimal brick has at least three vertices of degree three and conjectured that every minimal brick has at least cn vertices of degree three.
- 9. Communication Complexity : Improve bounds for the log-rank conjecture. The best known bound is

- 10. Approximation algorithms : Improve the approximation factor for the uniform sparsest cut problem. The best known factor is
.
Here are my conjectures for 2014 🙂
- Weak Conjecture : at least one of the above 10 problems will be resolved in 2014.
- Conjecture : at least five of the above 10 problems will be resolved in 2014.
- Strong Conjecture : All of the above 10 problems will be resolved in 2014.
Have fun !!
PolyTopix
In the last couple of years, I developed some (research) interest in recommendation algorithms and speech synthesis. My interests in these areas are geared towards developing an automated personalized news radio.
Almost all of us are interesting in consuming news. In this internet age, there is no dearth of news sources. Often we have too many sources. We tend to “read” news from several sources / news aggregators, spending several hours per week. Most of the time we are simply interested in the top and relevant headlines.
PolyTopix is my way of simplifying the process of consuming top and relevant news. The initial prototype is here. The website “reads” several news tweets (collected from different sources) and ordered based on a machine learning algorithm. Users can login and specify their individual interests (and zip code) to narrow down the news.
![]()
Try PolyTopix let me know your feedback. Here are some upcoming features :
- Automatically collect weather news (and local news) based on your location.
- Reading more details of most important news.
- News will be classified as exciting/sad/happy etc., (based on a machine learning algorithm) and read with the corresponding emotional voice.
Essentially PolyTopix is aimed towards a completely automated and personalized news radio, that can “read” news from across the world anytime with one click.
————————————————————————————————————————
Book Review of “Boosting : Foundations and Algorithms”
Following is my review of Boosting : Foundations and Algorithms (by Robert E. Schapire and Yoav Freund) to appear in the SIGACT book review column soon.

—————————————————————————————————————-
Book : Boosting : Foundations and Algorithms (by Robert E. Schapire and Yoav Freund)
Reviewer : Shiva Kintali
Introduction
You have k friends, each one earning a small amount of money (say 100 dollars) every month by buying and selling stocks. One fine evening, at a dinner conversation, they told you their individual “strategies” (after all, they are your friends). Is it possible to “combine” these individual strategies and make million dollars in an year, assuming your initial capital is same as your average friend ?
You are managing a group of k “diverse” software engineers each one with only an “above-average” intelligence. Is it possible to build a world-class product using their skills ?
The above scenarios give rise to fundamental theoretical questions in machine learning and form the basis of Boosting. As you may know, the goal of machine learning is to build systems that can adapt to their environments and learn from their experience. In the last five decades, machine learning has impacted almost every aspect of our life, for example, computer vision, speech processing, web-search, information retrieval, biology and so on. In fact, it is very hard to name an area that cannot benefit from the theoretical and practical insights of machine learning.
The answer to the above mentioned questions is Boosting, an elegant method for driving down the error of the combined classifier by combining a number of weak classifiers. In the last two decades, several variants of Boosting are discovered. All these algorithms come with a set of theoretical guarantees and made a deep practical impact on the advances of machine learning, often providing new explanations for existing prediction algorithms.
Boosting : Foundations and Algorithms, written by the inventors of Boosting, deals with variants of AdaBoost, an adaptive boosting method. Here is a quick explanation of the basic version of AdaBoost.
AdaBoost makes iterative calls to the base learner. It maintains a distribution over training examples to choose the training sets provided to the base learner on each round. Each training example is assigned a weight, a measure of importance of correctly classifying an example on the current round. Initially, all weights are set equally. On each round, the weights of incorrectly classified examples are increased so that, “hard” examples get successively higher weight. This forces the base learner to focus its attention on the hard example and drive down the generalization errors.
AdaBoost is fast and easy to implement and the only parameter to tune is the number of rounds. The actual performance of boosting is dependent on the data.
Summary
Chapter 1 provides a quick introduction and overview of Boosting algorithms with practical examples. The rest of the book is divided into four major parts. Each part is divided into 3 to 4 chapters.
Part I studies the properties and effectiveness of AdaBoost and theoretical aspects of minimizing its training and generalization errors. It is proved that AdaBoost drives the training error down very fast (as a function of the error rates of the weak classifiers) and the generalization error arbitrarily close to zero. Basic theoretical bounds on the generalization error show that AdaBoost overfits, however empirical studies show that AdaBoost does not overfit. To explain this paradox, a margin-based analysis is presented to explain the absence of overfitting.
Part II explains several properties of AdaBoost using game-theoretic interpretations. It is shown that the principles of Boosting are very intimately related to the classic min-max theorem of von Neumann. A two-player (the boosting algorithm and the weak learning algorithm) game is considered and it is shown that AdaBoost is a special case of a more general algorithm for playing a repeated game. By reversing the roles of the players, a solution is obtained for the online prediction model thus establishing a connection between Boosting and online learning. Loss minimization is studied and AdaBoost is interpreted as an abstract geometric framework for optimizing a particular objective function. More interestingly, AdaBoost is viewed as a special case of more general methods for optimization of an objective function such as coordinate descent and functional gradient descent.
Part III explains several methods of extending AdaBoost to handle classifiers with more than two output classes. AdaBoost.M1, AdaBoost.MH and AdaBoost.MO are presented along with their theoretical analysis and practical applications. RankBoost, an extension of AdaBoost to study ranking problems is studied. Such an algorithm is very useful, for example, to rank webpages based on their relevance to a given query.
Part IV is dedicated to advanced theoretical topics. Under certain assumptions, it is proved that AdaBoost can handle noisy-data and converge to the best possible classifier. An optimal boost-by-majority algorithm is presented. This algorithm is then modified to be adaptive leading to an algorithm called BrownBoost.
Many examples are given throughout the book to illustrate the empirical performance of the algorithms presented. Every chapter ends with Summary and Bibliography mentioning the related publications. There are well-designed exercises at the end of every chapter. Appendix briefly outlines some required mathematical background.
Opinion
Boosting book is definitely a very good reference text for researchers in the area of machine learning. If you are new to machine learning, I encourage you to read an introductory machine learning book (for example, Machine Learning by Tom M. Mitchell) to better understand and appreciate the concepts. In terms of being used in a course, a graduate-level machine learning course can be designed from the topics covered in this book. The exercises in the book can be readily used for such a course.
Overall this book is a stimulating learning experience. It has provided me new perspectives on theory and practice of several variants of Boosting algorithms. Most of the algorithms in this book are new to me and I had no difficulties following the algorithms and the corresponding theorems. The exercises at the end of every chapter made these topics much more fun to learn.
The authors did a very good job compiling different variants of Boosting algorithms and achieved a nice balance between theoretical analysis and practical examples. I highly recommend this book for anyone interested in machine learning.
—————————————————————————————————————-
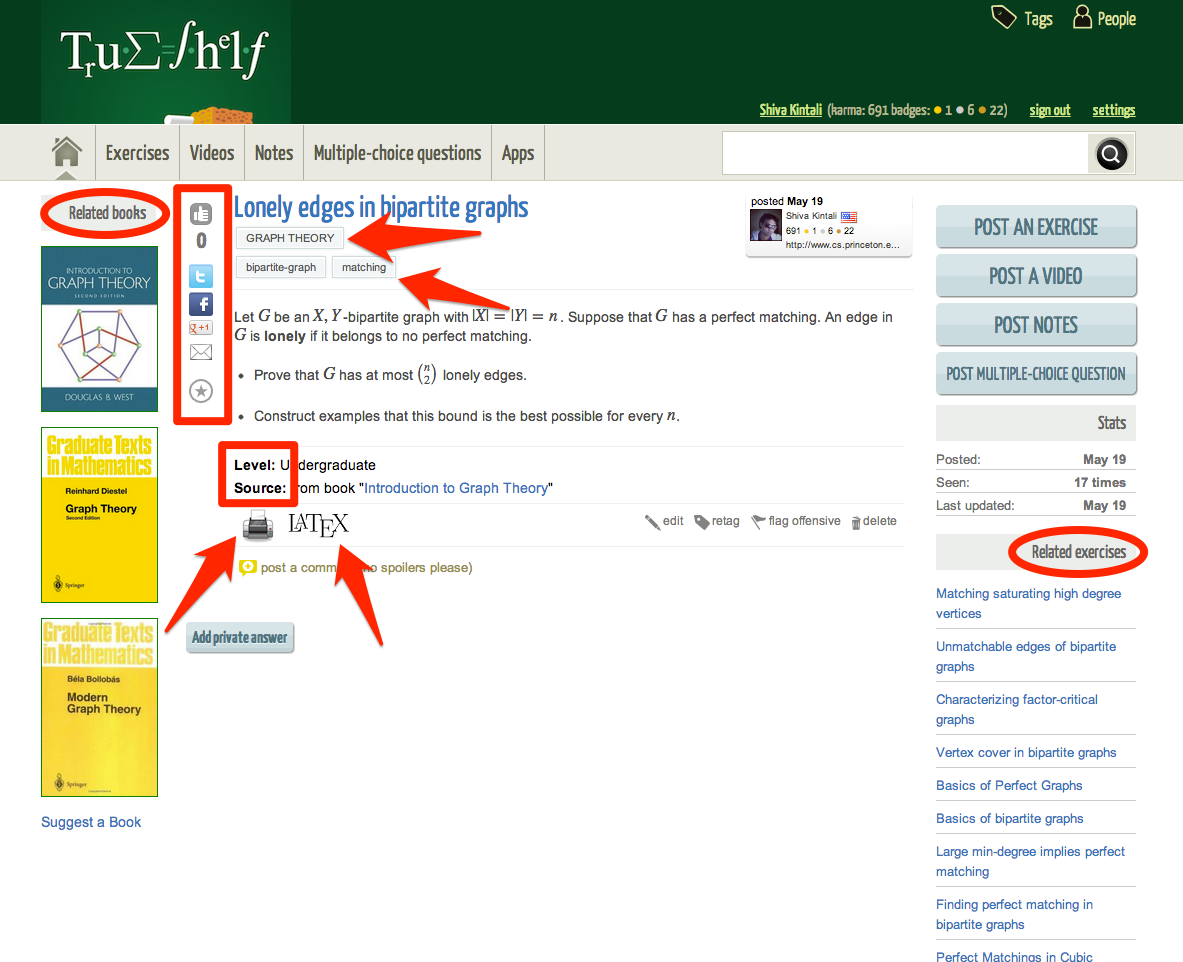
TrueShelf 1.0
One year back (on 6/6/12) I announced a beta version of TrueShelf, a social-network for sharing exercises and puzzles especially in mathematics and computer science. After an year of testing and adding new features, now I can say that TrueShelf is out of beta.
TrueShelf turned out to be a very useful website. When students ask me for practice problems (or books) on a particular topic, I simply point them to trueshelf and tell them the tags related to that topic. When I am advising students on research projects, I first tell them to solve all related problems (in the first couple of weeks) to prepare them to read research papers.
Here are the features in TrueShelf 1.0.
- Post an exercise (or) multiple-choice question (or) video (or) notes.
- Solve any multiple-choice question directly on the website.
- Add topic and tags to any post
- Add source or level (high-school/undergraduate/graduate/research).
- Show text-books related to a post
- Show related posts for every post.
- View printable version (or) LaTex version of any post.
- Email / Tweet / share on facebook (or) Google+ any post directly from the post.
- Add any post to your Favorites
- Like (a.k.a upvote) any post.
Feel free to explore TrueShelf, contribute new exercises and let me know if you have any feedback (or) new features you want to see. You can also follow TrueShelf on facebook, twitter and google+. Here is a screenshot highlighting the important features.